Probabilist: The Next Token
LLMの「次のトークン予測」を体験するWebゲーム。プレイヤーがAIの出力エンジンとなり、確率分布からトークンを選択して回答を生成。Gemma-2-2bモデルからリアルタイムでlogitsを抽出するサーバーレスGPU推論基盤を構築。
課題
LLMの仕組みは一般の人には理解しにくく、「AIがどのように文章を生成しているのか」「なぜAIは嘘をつくことがあるのか(ハルシネーション)」を直感的に把握することが困難。
ソリューション
ユーザーがLLMの「出力エンジン」となり、実際のモデルから抽出したlogitsベースの確率分布からトークンを選択する体験型ゲーム。Temperature・Top-K・Top-Pパラメータをリアルタイムで調整し、サンプリングの効果を体感できる。
技術スタック
プロジェクト概要
Probabilist: The Next Token は、大規模言語モデル(LLM)のトークン予測メカニズムを体験できるインタラクティブな教育ゲームです。
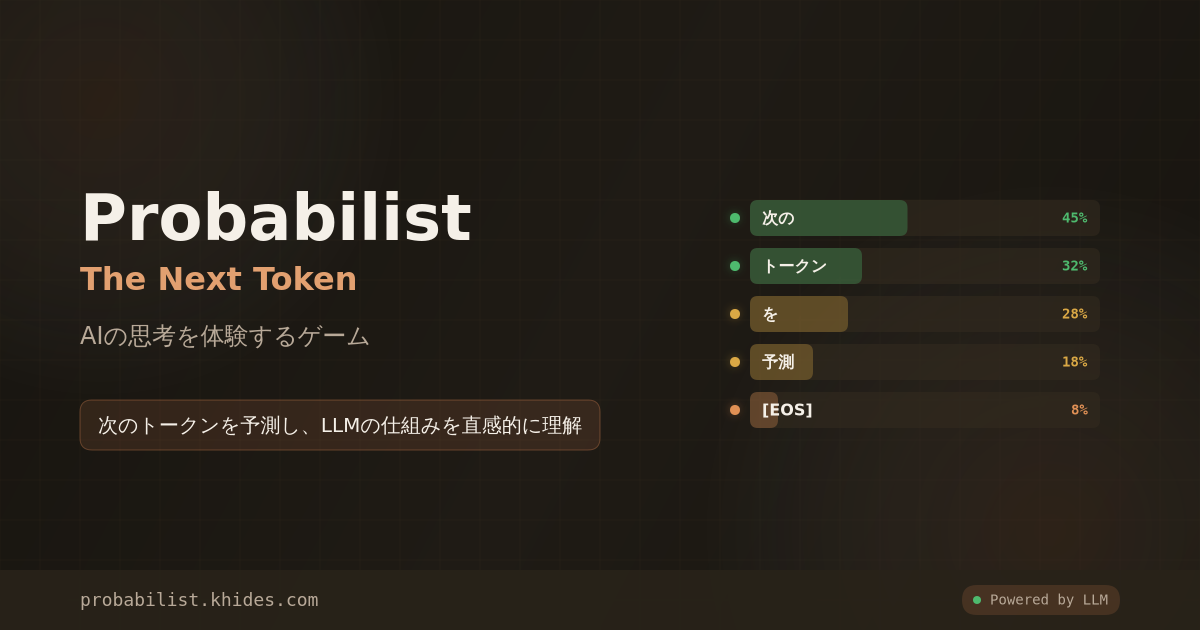
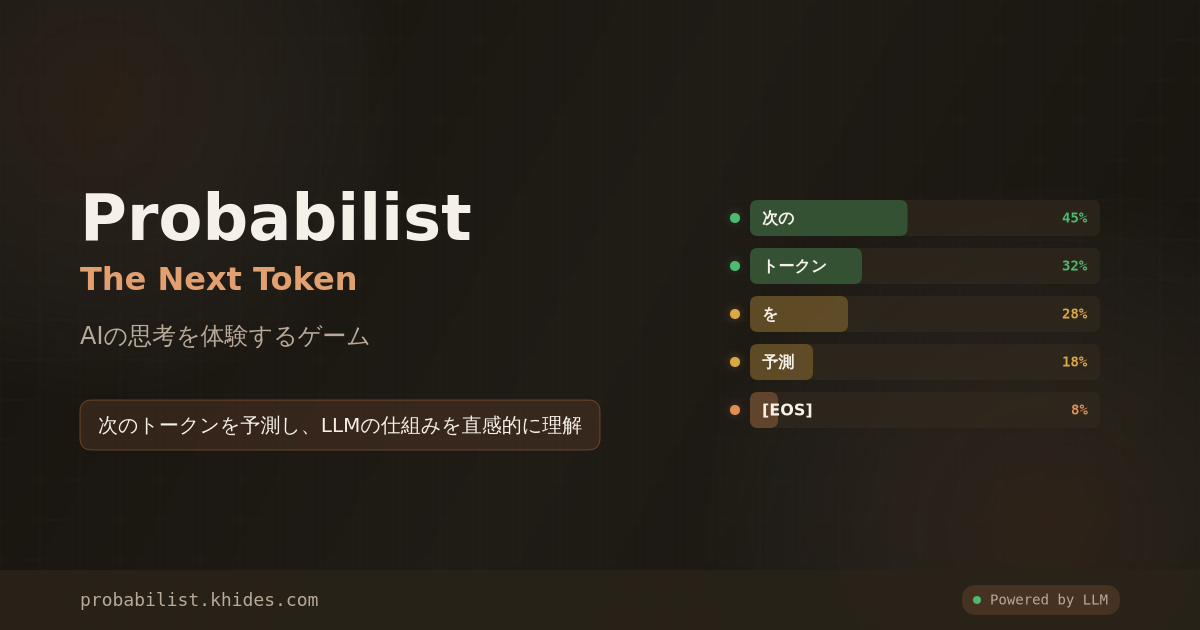
プレイヤーはLLMの「出力エンジン」となり、NPCからの質問に対して確率付きのトークン候補から選択し、回答を生成していきます。「正解」を選ぶのではなく、**「確率の波をどう渡り歩くか」**を楽しむゲームデザインにより、AIの動作原理を直感的に理解できます。
ゲームメカニクス
コア・ゲームループ
- プロンプト提示 — NPCから「おすすめのランチは?」などの問いが届く
- トークン選択 — 画面に次のトークン候補が5つ、確率(%)と共に表示
- 回答生成 — 選択したトークンが確定し、次の候補が表示される
- 終了と評価 — 文末トークン(EOS)選択か制限到達で終了、スコア算出
スコアリングシステム
- Perplexity(もっともらしさ) — 高確率トークンの選択で高得点
- Hallucination(幻覚ボーナス) — 低確率トークンによる「意外性」にボーナス
- Satisfaction(満足度) — プロンプトのキーワードに沿った回答で加点
低確率トークンほど高いボーナスを得られますが、文章の一貫性が崩れるとペナルティ。形態素解析(Sudachi)による日本語の文脈チェックで、単なるランダム選択ではなく「意味のある冒険」が報われる設計です。
サンプリングパラメータ
- Temperature — 出力のランダム性を制御(高いほどカオス)
- Top-K — 候補トークン数を制限
- Top-P — 累積確率でトークンをフィルタリング
これらをリアルタイムで調整し、サンプリングの効果を体感できます。
システムアーキテクチャ
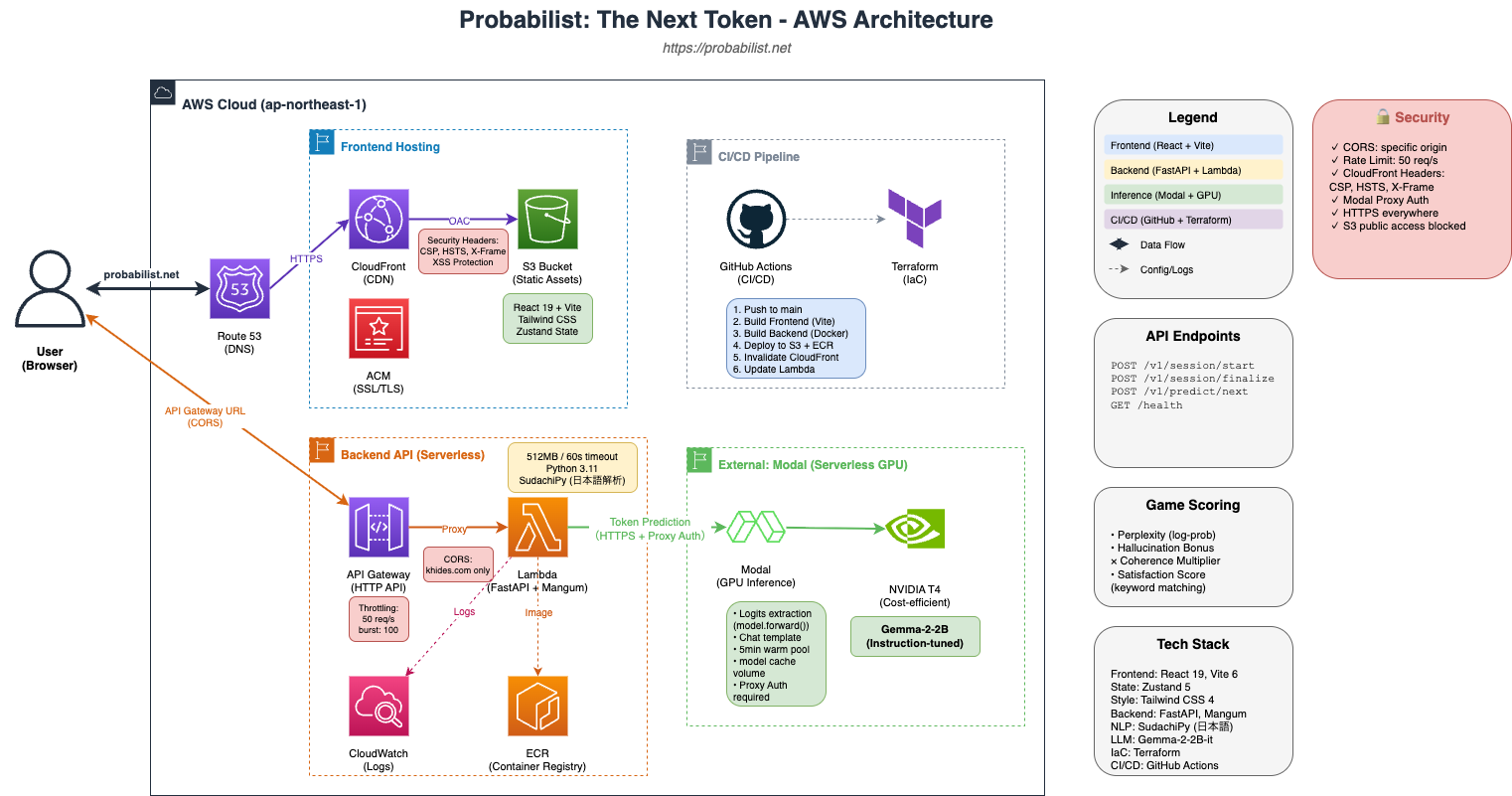
AWSを中心としたサーバーレスアーキテクチャで構築しています。
フロントエンド
- React 19 + TypeScript — 最新のReactで構築
- Vite 6(SWC) — 高速なビルドと開発体験
- Tailwind CSS v4 — ユーティリティファーストのスタイリング
- Zustand — 軽量な状態管理(ゲーム状態、パラメータ、チャット履歴)
- Framer Motion — スムーズなトークン選択アニメーション
バックエンド
- Python 3.11 + FastAPI — 高パフォーマンスな非同期API
- Pydantic v2 — 型安全なリクエスト/レスポンス検証
- Sudachi — 日本語形態素解析による一貫性チェック
- Mangum — AWS Lambda ASGIアダプタ
推論エンジン(プラグイン方式)
推論プロバイダーをプラグイン形式で実装し、環境に応じて切り替え可能:
- modal — 本番用サーバーレスGPU(Gemma-2-2b-it)
- huggingface — HF Inference API
- mock — 開発用ダミーデータ
Modal推論エンドポイント
LLM推論の核心技術として、model.forward()による直接的なlogits抽出を実装:
# 通常のgenerate()ではなく、forward()で生のlogitsを取得
with torch.no_grad():
outputs = self.model(**inputs)
logits = outputs.logits[:, -1, :] # 最後のトークン位置のみ
# Temperature適用とSoftmaxで確率分布を計算
logits = logits / temperature
probs = F.softmax(logits, dim=-1)これにより、LLMの「生の思考」である確率分布をフロントエンドに渡し、ユーザーが実際のAIの選択プロセスを体験できます。
インフラストラクチャ
- Frontend — AWS CloudFront + S3(グローバルCDN配信)
- Backend — AWS Lambda + API Gateway(サーバーレス、コスト効率◎)
- LLM推論 — Modal(サーバーレスGPU、T4インスタンス)
- IaC — Terraform(インフラのコード管理)
- CI/CD — GitHub Actions(自動デプロイ)
技術的ハイライト
Assistant Prefill(テキスト継続)
Gemma-2のチャットテンプレートを活用し、生成済みテキストを「アシスタントの回答の途中」として扱うことで、自然なテキスト継続を実現:
<bos><start_of_turn>user
おすすめのランチを教えてください<end_of_turn>
<start_of_turn>model
ランチ ← ここから続きを予測一貫性スコアリング
低確率トークンを選んでも、文章として成立していればボーナス維持。形態素解析で品詞の連接をチェックし、「意味のある冒険」と「破綻した文章」を区別します。
サーバーレス最適化
- Lambda + API Gatewayでコールドスタートを最小化
- Modal の scaledown_window でGPUインスタンスを5分間ウォーム保持
- モデルキャッシュ用Volumeで起動時間を短縮
成果
AIの仕組みを「体験」として提供することで、プログラミング初心者からAI研究者まで、LLMの動作原理を直感的に理解できる教育ツールとして機能しています。
「なぜAIは嘘をつくのか?」— 「あなたが0.5%の確率のトークンを選んだからです」という体験を通じて、ハルシネーションの本質を伝えています。