LLMの「次のトークン予測」をゲームにする — Probabilistの技術設計
はじめに
「AIはどうやって文章を生成しているのか?」
この問いに対して、「次のトークンを予測している」と説明しても、多くの人には実感が湧きません。
Probabilist: The Next Token は、この「次のトークン予測」を実際に体験できるWebゲームです。プレイヤーがLLMの「出力エンジン」となり、確率分布からトークンを選択していく——その体験を通じて、AIの動作原理を直感的に理解できます。
プレイはこちら: probabilist.net
この記事では、Probabilistの技術設計について詳しく解説します。
この記事でわかること:
- LLMからlogitsを抽出する仕組み
- サーバーレスGPU推論の設計
- ゲームとして成立させるスコアリング
- AWS + Modal によるインフラ構成
なぜ「次のトークン予測」をゲームにするのか
LLM(Large Language Model)は、本質的には「次に来る可能性が高いトークンを予測する」システムです。ChatGPTやClaudeが賢く見えるのは、この予測が驚くほど正確だから。
しかし、この仕組みには重要な含意があります:
- AIは「知っている」のではなく「予測している」
- 低確率のトークンを選べば、ハルシネーション(幻覚)が起きる
- Temperatureを上げれば、予測のばらつきが増える
言葉で説明するより、実際に体験したほうが理解が深まる——それがProbabilistの設計思想です。
システムアーキテクチャ
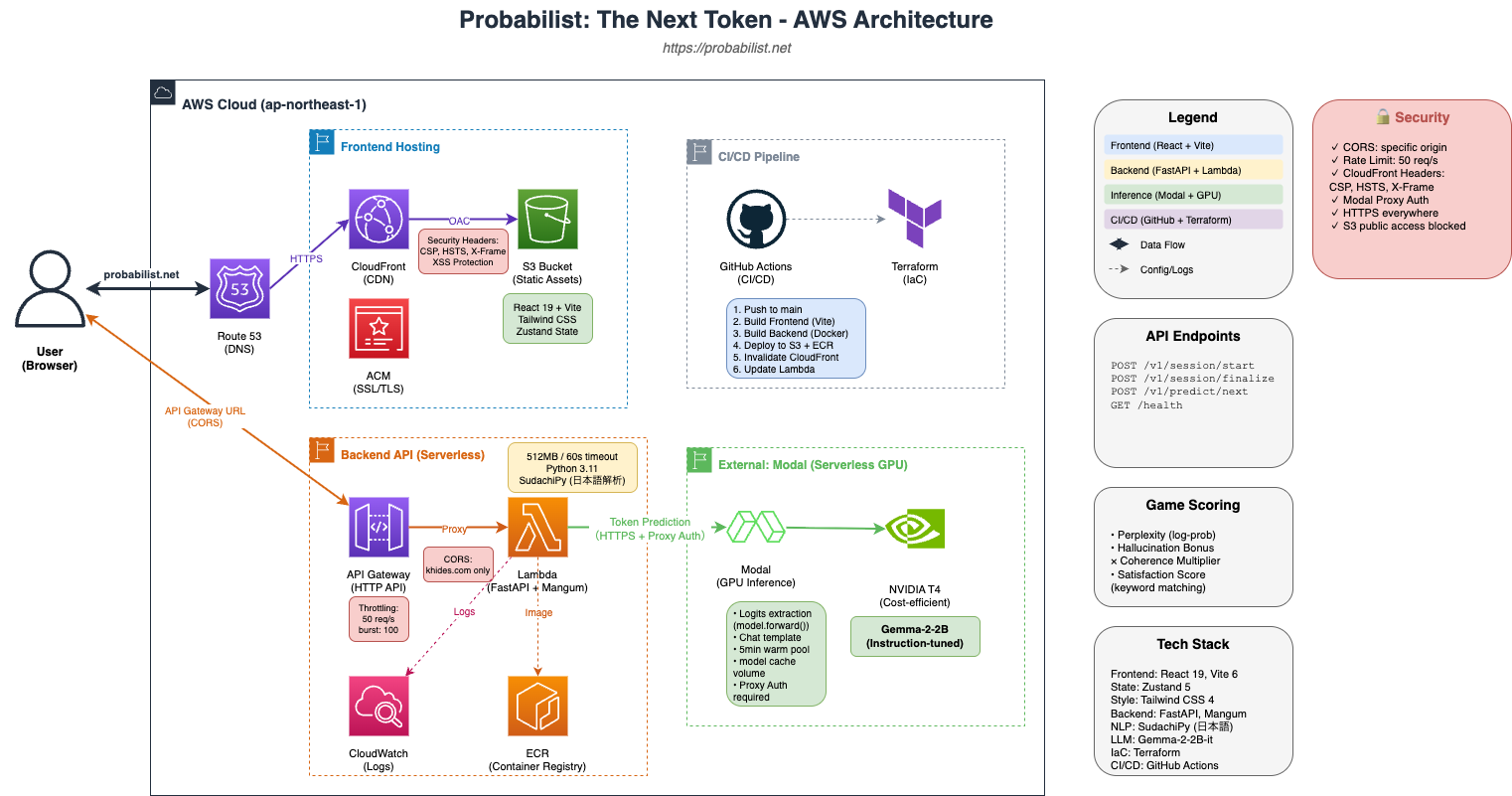
設計のポイント
- 完全サーバーレス — 使った分だけ課金、スケールも自動
- GPU推論の分離 — ModalでGPU処理を切り出し、コスト効率を最大化
- IaC管理 — Terraformでインフラをコード管理
核心技術:logitsの抽出
なぜgenerate()ではダメなのか
通常、LLMで文章を生成する場合は model.generate() を使います:
# 一般的な使い方
output = model.generate(input_ids, max_length=100)
generated_text = tokenizer.decode(output[0])しかし、これでは「次のトークンの確率分布」を取得できません。generate()は内部で複数のトークンを自動選択し、最終結果だけを返すからです。
forward()で生のlogitsを取得
Probabilistでは、model.forward() を使って1トークンずつ処理します:
# Probabilistのアプローチ
with torch.no_grad():
outputs = self.model(**inputs)
logits = outputs.logits[:, -1, :] # 最後のトークン位置のみ
# Temperature適用
if temperature != 1.0:
logits = logits / temperature
# Softmaxで確率に変換
probs = F.softmax(logits, dim=-1)
# Top-K候補を取得
top_probs, top_indices = torch.topk(probs[0], top_k)この方法により:
- 各トークンの正確な確率が取得できる
- Temperatureの効果をリアルタイムで反映できる
- ユーザーが選択するまで次のトークンが決まらない
Assistant Prefill:テキスト継続の実装
課題:選択したトークンから続きを予測したい
ユーザーが「ランチ」というトークンを選んだ場合、次の候補は「ランチ」の続きであるべきです。しかし、単純にプロンプトを連結すると:
User: おすすめのランチを教えてください
Assistant: ランチこの状態で generate() を呼ぶと、モデルは「Assistant: ランチ」を完結した回答として扱い、また最初から回答を始めようとしてしまいます。
解決策:Gemma-2のチャットテンプレート
Gemma-2の特殊トークンを活用して、「回答の途中」を表現します:
def _build_chat_prompt(self, prompt: str, generated_text: str) -> str:
template = (
f"<bos><start_of_turn>user\n"
f"{prompt}<end_of_turn>\n"
f"<start_of_turn>model\n"
f"{generated_text}" # ← end_of_turnを付けない!
)
return template<end_of_turn> を意図的に省略することで、モデルは「回答がまだ続く」と解釈し、自然なテキスト継続が可能になります。
スコアリングシステム
ゲームとして成立させるため、3軸のスコアリングを実装しました。
1. Perplexity(もっともらしさ)
選択したトークンの確率の逆数(対数)を基に計算:
log_probs = [math.log(max(t.probability / 100, 0.001)) for t in tokens]
avg_log_prob = sum(log_probs) / len(log_probs)
perplexity = int(math.exp(-avg_log_prob) * 10)高確率のトークンを選び続けるほど、Perplexityスコアが高くなります。
2. Hallucination(幻覚ボーナス)
低確率トークンを選ぶほどボーナス——ただし、文章が崩壊したらペナルティ:
def calculate_hallucination_bonus(tokens, full_text):
total_hal = 0
for t in tokens:
prob = t.probability
if prob >= 50:
bonus = 0 # 安全な選択
elif prob >= 20:
bonus = (50 - prob) * 1.0 # 軽いリスク
elif prob >= 5:
bonus = 30 + (20 - prob) * 2.5 # 中リスク
else:
bonus = 67.5 + (5 - prob) * 6.5 # 高リスク・高リターン
total_hal += bonus
# 一貫性チェック
coherence = check_text_coherence_advanced(full_text)
coherence_multiplier = 0.5 + (coherence * 0.5)
return int(total_hal * coherence_multiplier)3. Satisfaction(満足度)
プロンプトのキーワードが回答に含まれているか:
matched = sum(1 for k in keywords if k.lower() in full_text.lower())
satisfaction = int((matched / max(len(keywords), 1)) * 100)日本語の一貫性チェック
なぜ必要か
低確率トークンを選んでボーナスを得る戦略が有効ですが、「意味不明な文章」で高得点は取れないようにしたい。そこで、形態素解析による一貫性チェックを導入しました。
Sudachiによる実装
from sudachipy import Dictionary
def check_text_coherence_advanced(text: str) -> float:
tokenizer = Dictionary().create()
morphemes = tokenizer.tokenize(text)
# 品詞の連接をチェック
# 例:助詞の後に助詞が来たら減点
# 例:動詞の後に適切な助詞が来たら加点
return coherence_score # 0.0 ~ 1.0これにより、「低確率だけど文脈に合っている」選択が報われ、「ランダムに低確率を選ぶ」だけでは高得点が取れない設計になっています。
サーバーレスGPU推論
Modalの採用理由
GPU推論をAWS上で常時稼働させると、月額数万円のコストがかかります。しかし、Modalを使えば:
- 使った秒数だけ課金(T4インスタンス)
- 自動スケール(リクエストに応じてインスタンスが増減)
- ウォームアップ維持(scaledown_windowで5分間待機)
@app.cls(
image=image,
gpu="T4",
volumes={"/cache": model_cache},
timeout=120,
scaledown_window=300, # 5分間ウォーム保持
)
class InferenceEngine:
@modal.enter()
def load_model(self):
# モデルをキャッシュから読み込み
self.model = AutoModelForCausalLM.from_pretrained(
self.model_id,
cache_dir="/cache",
torch_dtype=torch.float16,
device_map="auto",
)コールドスタート対策
- モデルキャッシュ用Volume — 初回以降はダウンロード不要
- float16精度 — メモリ使用量を半減、ロード時間も短縮
- Lambda側のタイムアウト延長 — 60秒に設定
フロントエンドの状態管理
Zustandによるゲーム状態管理
複雑なゲーム状態をシンプルに管理するため、Zustandを採用:
interface GameState {
sessionId: string | null;
generatedTokens: GeneratedToken[];
currentCandidates: TokenCandidate[];
isGenerating: boolean;
parameters: GameParameters;
// Actions
sendMessage: (content: string) => Promise<void>;
selectToken: (token: string, probability: number) => Promise<void>;
updateParameter: <K extends keyof GameParameters>(
key: K,
value: GameParameters[K]
) => void;
}persistによる履歴保存
チャット履歴とパラメータ設定は、localStorageに永続化:
export const useGameStore = create<GameState>()(
persist(
(set, get) => ({
// ... state and actions
}),
{
name: "probabilist-game",
partialize: (state) => ({
parameters: state.parameters,
chatHistory: state.chatHistory,
}),
}
)
);CI/CDパイプライン
GitHub Actionsで、変更があったコンポーネントのみデプロイ:
jobs:
changes:
runs-on: ubuntu-latest
outputs:
frontend: ${{ steps.filter.outputs.frontend }}
backend: ${{ steps.filter.outputs.backend }}
modal: ${{ steps.filter.outputs.modal }}
steps:
- uses: dorny/paths-filter@v3
with:
filters: |
frontend:
- 'apps/web/**'
backend:
- 'apps/backend/**'
modal:
- 'apps/modal/**'
deploy-frontend:
needs: changes
if: needs.changes.outputs.frontend == 'true'
# S3 sync + CloudFront invalidation
deploy-backend:
needs: changes
if: needs.changes.outputs.backend == 'true'
# Docker build + ECR push + Lambda update
deploy-modal:
needs: changes
if: needs.changes.outputs.modal == 'true'
# modal deploy技術選定の振り返り
うまくいったこと
- Modalの採用 — GPU推論のコストを劇的に削減
- プラグイン型の推論プロバイダー — 開発時はmock、本番はmodalと切り替え可能
- Terraformによる IaC — 再現性のあるインフラ構築
改善の余地
- コールドスタート — 初回アクセス時に10秒程度の待機が発生
- モデルサイズ — Gemma-2-2bは軽量だが、より大きなモデルでの精度向上も検討
- 多言語対応 — 現在は日本語最適化、英語対応も視野に
おわりに
Probabilistは、「AIの仕組みを体験で伝える」という目標に向けて設計しました。
技術的には、model.forward()によるlogits抽出とサーバーレスGPU推論の組み合わせがポイントです。これにより、LLMの「生の思考」をリアルタイムでユーザーに提示できます。
「なぜAIは嘘をつくのか?」——「あなたが0.5%の確率のトークンを選んだからです」という体験は、どんな説明よりも直感的な理解をもたらします。
ぜひ一度、AIの「出力エンジン」になってみてください。
Probabilist: The Next Token でお待ちしています。