Probabilist: The Next Token
A web game to experience LLM next-token prediction. Players become the AI output engine, selecting tokens from probability distributions to generate responses. Built serverless GPU inference infrastructure that extracts logits in real-time from the Gemma-2-2b model.
The Challenge
LLM mechanics are difficult for general users to understand, making it hard to intuitively grasp "how AI generates text" and "why AI sometimes lies (hallucination)."
The Solution
An experiential game where users become the LLM "output engine," selecting tokens from logits-based probability distributions extracted from actual models. Adjust Temperature, Top-K, and Top-P parameters in real-time to experience sampling effects.
Tech Stack
Project Overview
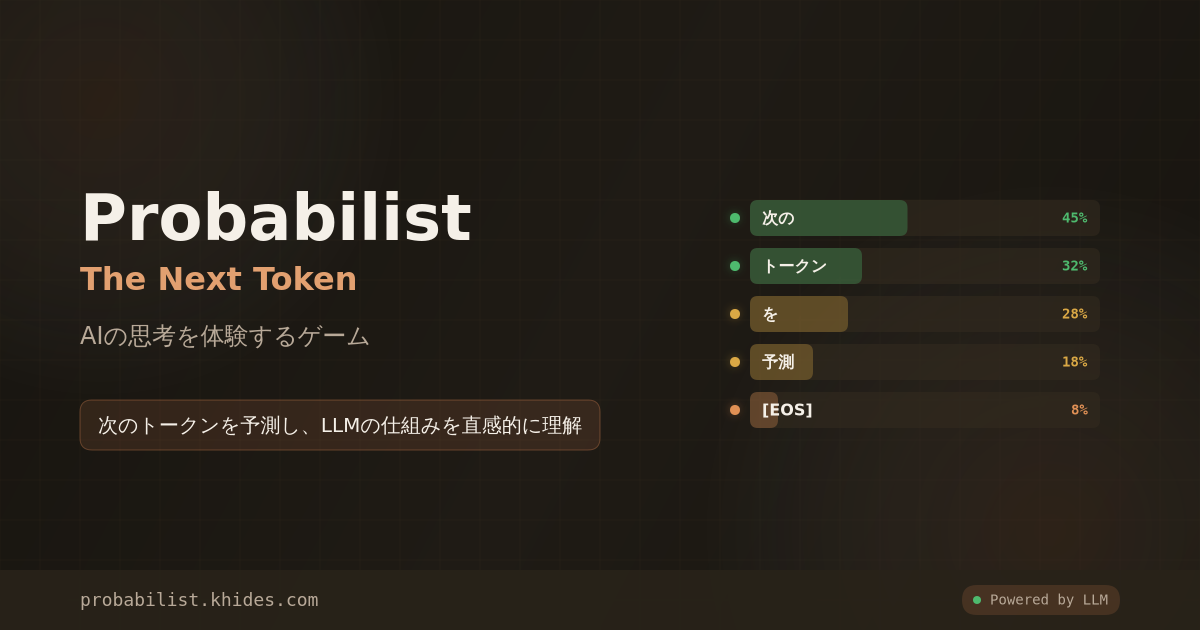
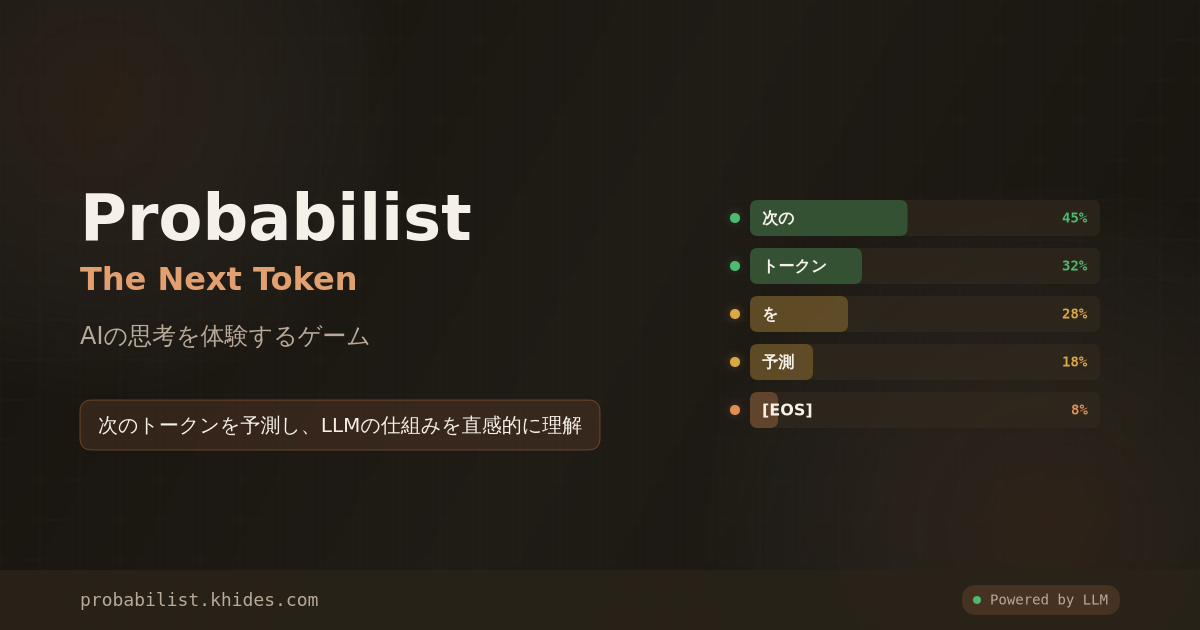
Probabilist: The Next Token is an interactive educational game that lets users experience how Large Language Models (LLMs) predict tokens.
Players become the LLM’s “output engine,” selecting from probability-weighted token candidates to generate responses to NPC questions. The game design focuses not on choosing the “correct” answer, but on enjoying “how to ride the waves of probability” — enabling intuitive understanding of AI’s operating principles.
Game Mechanics
Core Game Loop
- Prompt Presentation — An NPC asks a question like “What’s a good lunch recommendation?”
- Token Selection — Five next-token candidates appear with probabilities (%)
- Response Generation — Selected token is confirmed, next candidates appear
- Completion & Scoring — Game ends on EOS token or limit reached, scores calculated
Scoring System
- Perplexity (Plausibility) — High scores for choosing high-probability tokens
- Hallucination (Surprise Bonus) — Bonus for “unexpected” low-probability choices
- Satisfaction — Points for responses aligned with prompt keywords
Lower probability tokens yield higher bonuses, but coherence breakdown incurs penalties. Morphological analysis (Sudachi) checks Japanese context, rewarding “meaningful adventures” rather than random selection.
Sampling Parameters
- Temperature — Controls output randomness (higher = more chaotic)
- Top-K — Limits candidate token count
- Top-P — Filters tokens by cumulative probability
Adjust these in real-time to experience sampling effects firsthand.
System Architecture
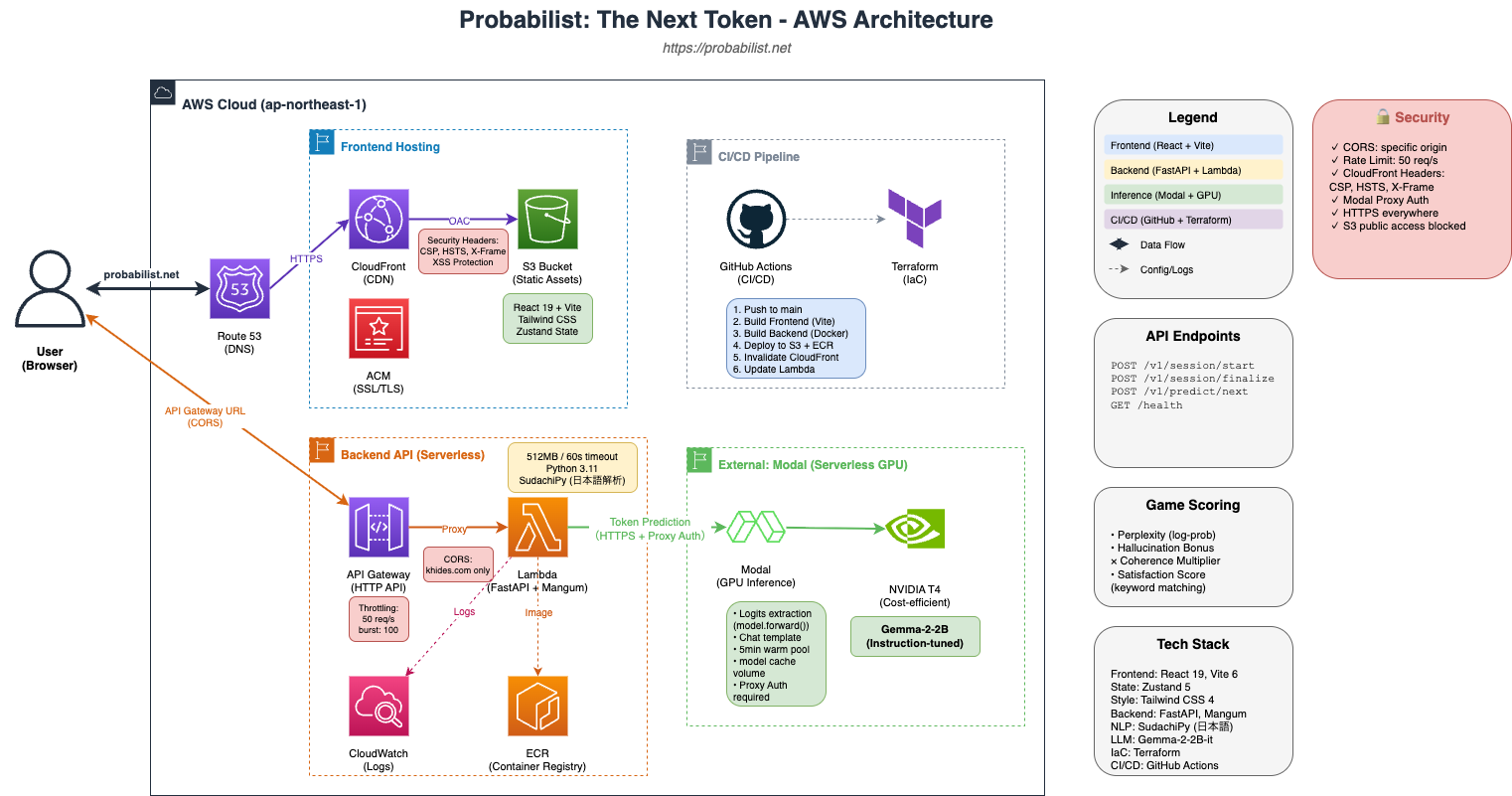
Built on a serverless architecture centered around AWS.
Frontend
- React 19 + TypeScript — Built with the latest React
- Vite 6 (SWC) — Fast builds and development experience
- Tailwind CSS v4 — Utility-first styling
- Zustand — Lightweight state management (game state, parameters, chat history)
- Framer Motion — Smooth token selection animations
Backend
- Python 3.11 + FastAPI — High-performance async API
- Pydantic v2 — Type-safe request/response validation
- Sudachi — Japanese morphological analysis for coherence checking
- Mangum — AWS Lambda ASGI adapter
Inference Engine (Plugin Architecture)
Inference providers implemented as plugins, switchable by environment:
- modal — Production serverless GPU (Gemma-2-2b-it)
- huggingface — HF Inference API
- mock — Development dummy data
Modal Inference Endpoint
The core inference technology implements direct logits extraction via model.forward():
# Use forward() instead of generate() to get raw logits
with torch.no_grad():
outputs = self.model(**inputs)
logits = outputs.logits[:, -1, :] # Last token position only
# Apply temperature and calculate probability distribution via Softmax
logits = logits / temperature
probs = F.softmax(logits, dim=-1)This passes the LLM’s “raw thinking” — probability distributions — to the frontend, letting users experience the actual AI selection process.
Infrastructure
- Frontend — AWS CloudFront + S3 (global CDN delivery)
- Backend — AWS Lambda + API Gateway (serverless, cost-efficient)
- LLM Inference — Modal (serverless GPU, T4 instance)
- IaC — Terraform (infrastructure as code)
- CI/CD — GitHub Actions (automated deployment)
Technical Highlights
Assistant Prefill (Text Continuation)
Leveraging Gemma-2’s chat template, generated text is treated as “mid-response by the assistant,” enabling natural text continuation:
<bos><start_of_turn>user
What's a good lunch recommendation?<end_of_turn>
<start_of_turn>model
Lunch ← Prediction continues from hereCoherence Scoring
Even when choosing low-probability tokens, bonus is maintained if the text remains coherent. Morphological analysis checks part-of-speech connections, distinguishing “meaningful adventures” from “broken sentences.”
Serverless Optimization
- Lambda + API Gateway minimizes cold starts
- Modal’s scaledown_window keeps GPU instances warm for 5 minutes
- Model cache Volume reduces startup time
Results
By providing AI mechanics as an “experience,” this serves as an educational tool enabling intuitive understanding of LLM operating principles — from programming beginners to AI researchers.
“Why does AI lie?” — Through the experience of “because you chose the 0.5% probability token,” users grasp the essence of hallucination.