Turning LLM "Next Token Prediction" Into a Game — The Technical Design of Probabilist
Introduction
“How does AI generate text?”
When you explain that it “predicts the next token,” most people don’t really get it.
Probabilist: The Next Token is a web game that lets you actually experience this “next token prediction.” Players become the LLM’s “output engine,” selecting tokens from probability distributions — through this experience, you intuitively understand how AI works.
Play here: probabilist.net
This article provides a detailed look at Probabilist’s technical design.
What you’ll learn:
- How to extract logits from LLMs
- Serverless GPU inference architecture
- Scoring system design for gameplay
- AWS + Modal infrastructure setup
Why Turn “Next Token Prediction” Into a Game?
LLMs (Large Language Models) are essentially systems that “predict the most likely next token.” ChatGPT and Claude appear intelligent because these predictions are remarkably accurate.
However, this mechanism has important implications:
- AI doesn’t “know” — it “predicts”
- Choosing low-probability tokens causes hallucination
- Raising Temperature increases prediction variance
Rather than explaining with words, experiencing it firsthand leads to deeper understanding — that’s Probabilist’s design philosophy.
System Architecture
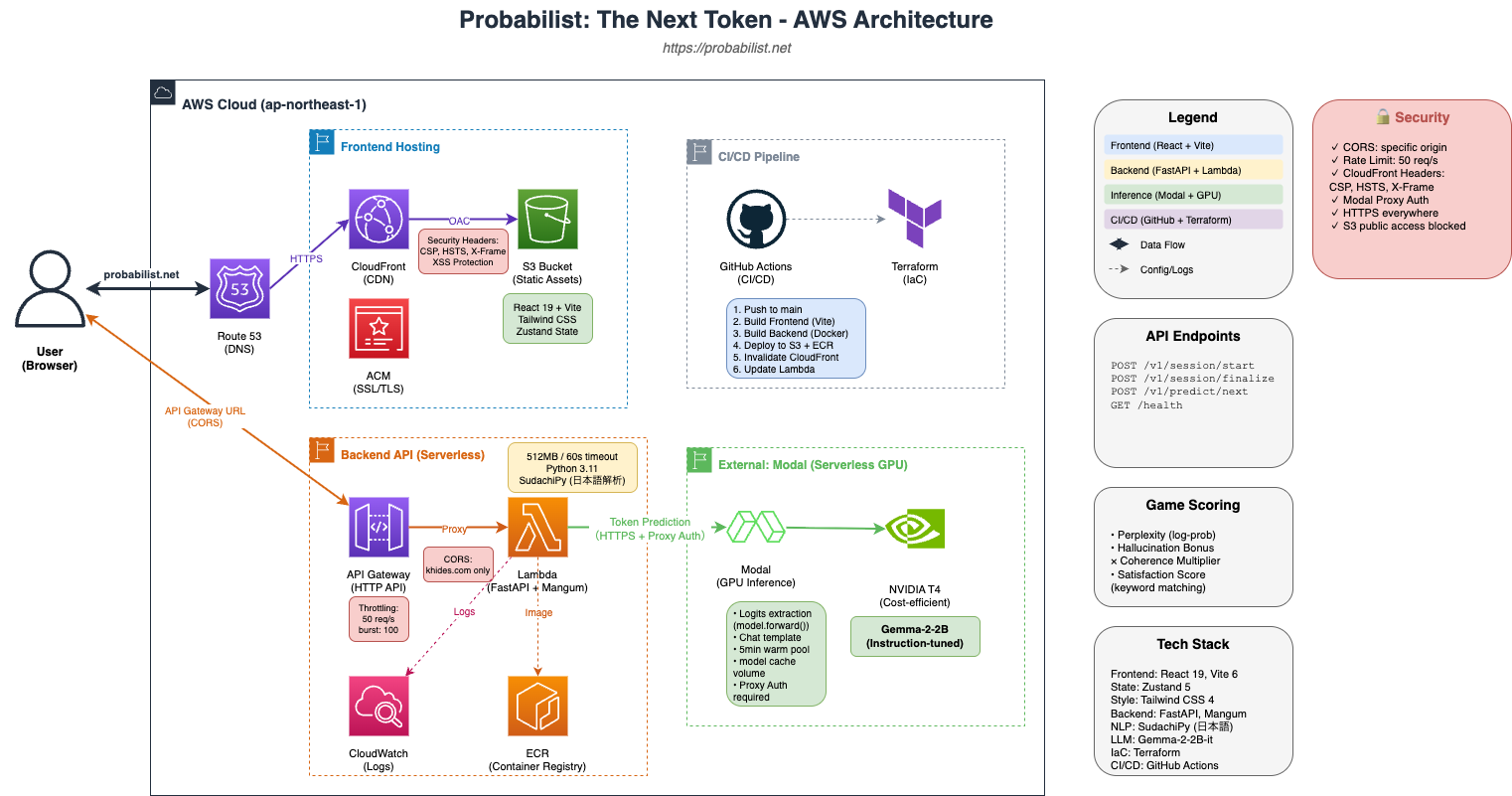
Design Points
- Fully Serverless — Pay only for what you use, auto-scaling
- Separated GPU Inference — Modal handles GPU processing, maximizing cost efficiency
- IaC Management — Terraform for infrastructure as code
Core Technology: Logits Extraction
Why generate() Won’t Work
Normally, you use model.generate() to generate text with LLMs:
# Typical usage
output = model.generate(input_ids, max_length=100)
generated_text = tokenizer.decode(output[0])However, this doesn’t give you the “probability distribution for the next token.” generate() automatically selects multiple tokens internally and only returns the final result.
Getting Raw Logits with forward()
Probabilist uses model.forward() to process one token at a time:
# Probabilist's approach
with torch.no_grad():
outputs = self.model(**inputs)
logits = outputs.logits[:, -1, :] # Last token position only
# Apply Temperature
if temperature != 1.0:
logits = logits / temperature
# Convert to probabilities via Softmax
probs = F.softmax(logits, dim=-1)
# Get Top-K candidates
top_probs, top_indices = torch.topk(probs[0], top_k)This approach enables:
- Accurate probability for each token
- Real-time Temperature effects
- Next token undetermined until user selection
Assistant Prefill: Implementing Text Continuation
The Challenge: Predicting Continuation from Selected Token
When a user selects “Lunch” as a token, the next candidates should continue from “Lunch.” But simply concatenating to the prompt:
User: What's a good lunch recommendation?
Assistant: LunchIf you call generate() in this state, the model treats “Assistant: Lunch” as a complete response and tries to start a new answer from scratch.
Solution: Gemma-2’s Chat Template
We leverage Gemma-2’s special tokens to express “mid-response”:
def _build_chat_prompt(self, prompt: str, generated_text: str) -> str:
template = (
f"<bos><start_of_turn>user\n"
f"{prompt}<end_of_turn>\n"
f"<start_of_turn>model\n"
f"{generated_text}" # ← Intentionally omit end_of_turn!
)
return templateBy intentionally omitting <end_of_turn>, the model interprets “the response continues,” enabling natural text continuation.
Scoring System
To make it work as a game, we implemented three-axis scoring.
1. Perplexity (Plausibility)
Calculated based on the inverse (logarithm) of selected token probabilities:
log_probs = [math.log(max(t.probability / 100, 0.001)) for t in tokens]
avg_log_prob = sum(log_probs) / len(log_probs)
perplexity = int(math.exp(-avg_log_prob) * 10)Consistently choosing high-probability tokens yields higher Perplexity scores.
2. Hallucination (Surprise Bonus)
Lower probability tokens give higher bonuses — but coherence breakdown incurs penalties:
def calculate_hallucination_bonus(tokens, full_text):
total_hal = 0
for t in tokens:
prob = t.probability
if prob >= 50:
bonus = 0 # Safe choice
elif prob >= 20:
bonus = (50 - prob) * 1.0 # Light risk
elif prob >= 5:
bonus = 30 + (20 - prob) * 2.5 # Medium risk
else:
bonus = 67.5 + (5 - prob) * 6.5 # High risk, high reward
total_hal += bonus
# Coherence check
coherence = check_text_coherence_advanced(full_text)
coherence_multiplier = 0.5 + (coherence * 0.5)
return int(total_hal * coherence_multiplier)3. Satisfaction
Whether prompt keywords appear in the response:
matched = sum(1 for k in keywords if k.lower() in full_text.lower())
satisfaction = int((matched / max(len(keywords), 1)) * 100)Japanese Coherence Checking
Why It’s Needed
While choosing low-probability tokens for bonuses is a valid strategy, we don’t want “meaningless text” to score high. So we introduced morphological analysis-based coherence checking.
Implementation with Sudachi
from sudachipy import Dictionary
def check_text_coherence_advanced(text: str) -> float:
tokenizer = Dictionary().create()
morphemes = tokenizer.tokenize(text)
# Check part-of-speech connections
# Example: Particle after particle = penalty
# Example: Appropriate particle after verb = bonus
return coherence_score # 0.0 ~ 1.0This rewards “low-probability but contextually appropriate” choices while preventing “randomly selecting low-probability tokens” from scoring high.
Serverless GPU Inference
Why Modal
Running GPU inference on AWS continuously costs tens of thousands of yen per month. But with Modal:
- Pay per second (T4 instance)
- Auto-scaling (instances scale with requests)
- Warm maintenance (scaledown_window keeps warm for 5 minutes)
@app.cls(
image=image,
gpu="T4",
volumes={"/cache": model_cache},
timeout=120,
scaledown_window=300, # Keep warm for 5 minutes
)
class InferenceEngine:
@modal.enter()
def load_model(self):
# Load model from cache
self.model = AutoModelForCausalLM.from_pretrained(
self.model_id,
cache_dir="/cache",
torch_dtype=torch.float16,
device_map="auto",
)Cold Start Countermeasures
- Model cache Volume — No download needed after first time
- float16 precision — Halves memory usage, faster loading
- Extended Lambda timeout — Set to 60 seconds
Frontend State Management
Game State with Zustand
We adopted Zustand for simple management of complex game state:
interface GameState {
sessionId: string | null;
generatedTokens: GeneratedToken[];
currentCandidates: TokenCandidate[];
isGenerating: boolean;
parameters: GameParameters;
// Actions
sendMessage: (content: string) => Promise<void>;
selectToken: (token: string, probability: number) => Promise<void>;
updateParameter: <K extends keyof GameParameters>(
key: K,
value: GameParameters[K]
) => void;
}History Persistence with persist
Chat history and parameter settings are persisted to localStorage:
export const useGameStore = create<GameState>()(
persist(
(set, get) => ({
// ... state and actions
}),
{
name: "probabilist-game",
partialize: (state) => ({
parameters: state.parameters,
chatHistory: state.chatHistory,
}),
}
)
);CI/CD Pipeline
GitHub Actions deploys only components that changed:
jobs:
changes:
runs-on: ubuntu-latest
outputs:
frontend: ${{ steps.filter.outputs.frontend }}
backend: ${{ steps.filter.outputs.backend }}
modal: ${{ steps.filter.outputs.modal }}
steps:
- uses: dorny/paths-filter@v3
with:
filters: |
frontend:
- 'apps/web/**'
backend:
- 'apps/backend/**'
modal:
- 'apps/modal/**'
deploy-frontend:
needs: changes
if: needs.changes.outputs.frontend == 'true'
# S3 sync + CloudFront invalidation
deploy-backend:
needs: changes
if: needs.changes.outputs.backend == 'true'
# Docker build + ECR push + Lambda update
deploy-modal:
needs: changes
if: needs.changes.outputs.modal == 'true'
# modal deployReflecting on Technology Choices
What Worked Well
- Adopting Modal — Dramatically reduced GPU inference costs
- Plugin-style inference providers — Switch between mock for dev, modal for production
- Terraform IaC — Reproducible infrastructure builds
Room for Improvement
- Cold starts — ~10 second wait on first access
- Model size — Gemma-2-2b is lightweight; considering larger models for accuracy
- Multilingual support — Currently optimized for Japanese; English support planned
Conclusion
Probabilist was designed with the goal of “conveying AI mechanics through experience.”
Technically, the combination of logits extraction via model.forward() and serverless GPU inference is key. This enables presenting the LLM’s “raw thinking” to users in real-time.
“Why does AI lie?” — The experience of “because you chose the 0.5% probability token” provides more intuitive understanding than any explanation.
Try becoming an AI “output engine” yourself.
We’ll see you at Probabilist: The Next Token.